Crawling dan Indexing Berbasis Apache Nutch, Elasticsearch, dan MongoDB
Pada artikel sebelumnya (Membangun Mesin Pencari dengan Kombinasi Apache Nutch, Elasticsearch, dan MongoDB) telah dibahas secara singkat tentang apa itu Apache Nutch, apa itu Elasticsearch, dan Apa itu MongoDB. Pada bagian 2 ini akan dibahas langkah demi langkah tentang bagaimana membangun web crawler dengan Apache Nutch, melakukan crawling terhadap website yang dijadikan target, kemudian menyimpan hasil crawling tersebut dalam bentuk data terstruktur menggunakan MongoDB, serta membangun mensin pencari menggunakan Elasticsearch sehingga dapat dilakukan penelisikan dan analisis terhadap data-data hasil crawling tersebut.
Software yang harus disiapkan sebelumnya diantaranya (harus sudah siap digunakan) :
Selanjutnya, silakan unduh komponen-komponen software open-source yang dibutuhkan untuk membangun web crawler, mesin pencari, dan database NoSQL berbasis dokumen, yaitu:
Nah, sampai disini, isi website yang dijadikan target crawling sudah berhasil disedot/diserap dengan Nutch dan telah di-index oleh Elasticsearch. Selanjutnya, data hasil crawling dapat di-visualisasikan dengan menggunakan Kibana.
Gunakan web browser untuk mengakses Kibana di http://localhost:5601. Namun, sebelum data yang telah di-index Elasticsearch dapat ditampilkan, Kibana harus diberitahu nama index dari dataset yang ingin ditampilkan. Pada "Configure an index pattern" di halaman Kibana (http://localhost:5601), uncheck item "Index contains time-based events" dan ketik "nutch" pada field "Index name or pattern". Nama index "nutch" disini harus sama dengan nama index yang telah dikonfigurasi di nutch-site.xml pada property elastic.index seperti berikut:
Catatan:
Apache-nutch-2.3.1 TIDAK kompatibel dengan elasticsearch-2.3.3 Pasangan yang sudah dipastikan kompatibel adalah: apache-nutch-2.3.1 + elasticsearch-1.4.4 + kibana-4.1.8 + mongodb-3.2.1
Demikian, semoga bermanfaat. Silakan share pertanyaan, opini, maupun pengalaman anda via kolom komentar. Terima kasih.
Setelah sukses pada Bagian 2 ini, silakan lanjut ke Bagian 3 (Apache Nutch Crawl Script: Web Crawling hanya dengan Satu Command).
Software yang harus disiapkan sebelumnya diantaranya (harus sudah siap digunakan) :
1. OS jenis Linux, bisa CentOS 7, Ubuntu 14.0.4 LTS, Mac OSX 10.9 (Mavericks)
2. Java, dalam hal ini digunakan Oracle JRE 1.8 atau Oracle JRE 1.7
3. Apache Ant Java dan Apache Ant harus sudah diinstal dengan benar di OS yang digunakan. Disini tidak akan dibahas tentang cara-cara instal Java maupun Apache Ant.
2. Java, dalam hal ini digunakan Oracle JRE 1.8 atau Oracle JRE 1.7
3. Apache Ant Java dan Apache Ant harus sudah diinstal dengan benar di OS yang digunakan. Disini tidak akan dibahas tentang cara-cara instal Java maupun Apache Ant.
Selanjutnya, silakan unduh komponen-komponen software open-source yang dibutuhkan untuk membangun web crawler, mesin pencari, dan database NoSQL berbasis dokumen, yaitu:
1. Mongodb-3.2.1 dapat diunduh gratis dari website MongoDB.
2. Elasticsearch-1.4.4 dapat diunduh gratis dari website Elasticsearch.
3. Kibana-4.1.8 dapat diunduh gratis dari website Kibana.
4. Apache Nutch-2.3.1 dapat diunduh gratis dari website Apache Nutch.
Dengan alasan kompatibilitas, dianjurkan untuk mengunduh versi yang sama persis dengan yang digunakan pada artikel ini. 2. Elasticsearch-1.4.4 dapat diunduh gratis dari website Elasticsearch.
3. Kibana-4.1.8 dapat diunduh gratis dari website Kibana.
4. Apache Nutch-2.3.1 dapat diunduh gratis dari website Apache Nutch.
Langkah-langkah Crawling, menyimpan hasilnya dalam database MongoDB, serta membangun mesin pencari menggunakan Elasticsearch:
Setelah berhasil mengunduh semua komponen software open-source yang dibutuhkan dengan versi yang sesuai, silakan ikuti langkah-langkah berikut: 1. Instal Mongodb versi 3.2.1
Uncompress file Mongodb-3.2.1 yang sudah di-download dari website MongoDB, pindahkan direktori hasil uncompress ke home directory user.
Jika command-command diatas sudah dapat berjalan normal tanpa eror, berarti instal Mongodb sudah sukses, dan Mongodb sudah siap melayani permintan client. Pada contoh disini, OS yang digunakan adalah OSX 10.9 Mavericks dan kebetulan pada server MongoDB yang diinstal sudah dibuat dua database, yaitu: dias dan nutch.
2. Instal Elasticsearch versi 1.4.4
Pertama-tama, Uncompress Elasticsearch-1.4.4 yang telah diunduh dari website Elasticsearh dan pindahkan direktori hasil uncompress ke home directory user.
Ketiga, jalankan Elasticsearch dengan command berikut:
Pertama, uncompress Kibana-4.1.8 yang telah diunduh dari website Kibana dan pindahkan direktori hasil uncompress ke home directory user.
4. Instal Apache Nutch versi 2.3.1
Pertama, uncompress file Apache Nutch versi 2.3.1 yang telah diunduh dari website Apache Nutch ke home directory user.
Ketiga, pastikan bahwa MongoDB gora-mongodb dependency sudah dinyatakan dalam file
Keempat, pastikan bahwa MongoStore sudah di-set sebagai default datastore dalam file
Kelima, tiba saatnya untuk meng-compile apache-nutch-2.3.1 source code dengan menjalankan perintah:
Waktu yang diperlukan untuk meng-compile source code apache-nutch-2.3.1 bisa bervariasi bergantung environment sistem yang digunakan, dan perlu diingat sekali lagi bahwa komputer yang digunakan harus tetap terhubung dengan Internet selama proses compile. Ada kemungkinan akan muncul error message seperti berikut:
Error message ini muncul karena sonar jar tidak ada pada salah satu classpaths (lihat build.xml, baris 883)
Error message diatas bisa saja diabaikan dan compile apache-nutch-2.3.1 tetap berjalan karena file yang dibutuhkan oleh error message tersebut hanya diperlukan jika menjalankan "sonar" target. Namun demikian, ada satu cara sederhana untuk menghilangkannya yaitu dengan menghapus taskdef dalam "sonar" target (pada file build.xml). Dengan begitu, error message tersebut tidak akan muncul lagi.
5. Memulai crawling atau menyerap isi website yang dijadikan target.
Sebelum dapat memulai crawling atau menyerap isi website yang dijadikan target menggunakan Apache Nutch, ada 2 konfigurasi yang mesti di-edit, yaitu:
Pertama, edit crawl properties, paling tidak crawler-nya diberi nama sehingga dapat dikenali oleh servers lain.
Kedua, tentukan URL-URL yang akan dijadikan target crawling.
Mari dimulai dengan konfigurasi pertama, yaitu mengedit crawl properties dengan terlebih dahulu masuk ke direktori apache-nutch-2.3.1 hasil compile.
File konfigurasi dalam direktori conf yang harus diedit adalah
Selanjutnya, lalukan konfigurasi kedua, yaitu menentukan URL-URL yang akan dijadikan target crawling. URL-URL ini dicantumkan dalam file
Ini adalah ronde pertama proses crawling yang melewati 6 langkah didalamnya, yaitu: menginjeksi seed URLs ke dalam crawldb, men-generate URLs dari seed URLs, Fetching, Parsing, Update database, dan Indexing. Keenam langkah yang berurutan ini mesti dijalankan secara berulang-ulang hingga seluruh isi website yang dijadikan target selesai di-index.
Uncompress file Mongodb-3.2.1 yang sudah di-download dari website MongoDB, pindahkan direktori hasil uncompress ke home directory user.
/Users/hennywijaya/mongodb/mongodb-osx-x86_64-3.2.1Start Mongodb dengan command
bin/mongod: cd ~/mongodb/mongodb-osx-x86_64-3.2.1/Start Mongodb Shell dengan command
bin/mongod
bin/mongo, kemudian coba execute command show dbs untuk menampilkan nama semua database yang sudah ada. bin/mongo
MongoDB shell version: 3.2.1
connecting to: test
Server has startup warnings:
2016-06-25T05:30:28.295+0900 I CONTROL [initandlisten]
2016-06-25T05:30:28.295+0900 I CONTROL [initandlisten]** WARNING: soft rlimits too low. Number of files is 256, should be at least 1000
> show dbs
dias 0.124GB
local 0.000GB
nutch 0.005GB
2. Instal Elasticsearch versi 1.4.4
Pertama-tama, Uncompress Elasticsearch-1.4.4 yang telah diunduh dari website Elasticsearh dan pindahkan direktori hasil uncompress ke home directory user.
/Users/hennywijaya/elasticsearch/elasticsearch-1.4.4Kedua, edit file konfigurasi Elasticsearch yaitu
elasticsearch.yml yang berada di direktori config. cd ~/elasticsearch/elasticsearch-1.4.4/configFile konfigurasi
ls
elasticsearch.yml logging.yml
elasticsearch.yml diedit dengan meng-uncomment item-item berikut (sesuaikan dengan environment yang digunakan): cluster.name: nasional-security-analysis
node.name: "wijaya"
node.master: true
node.data: true
path.conf: /Users/hennywijaya/elasticsearch/elasticsearch-1.4.4/config
path.data: /Users/hennywijaya/elasticsearch/elasticsearch-1.4.4/data
cd ~/elasticsearch/elasticsearch-1.4.4/Jika Elasticsearch berjalan normal, maka Elasticsearch akan dapat diakses via web browser dengan URL
bin/elasticsearch
http://localhost:9200 atau diakses via command line berikut: hennywijaya$ curl -XGET 'http://localhost:9200'3. Instal Kibana versi 4.1.8
{
"status" : 200,
"name" : "wijaya",
"cluster_name" : "nasional-security-analysis",
"version" : {
"number" : "1.4.4",
"build_hash" : "c88f77ffc81301dfa9dfd81ca2232f09588bd512",
"build_snapshot" : false,
"lucene_version" : "4.10.3"
},
"tagline" : "You Know, for Search"
}
Pertama, uncompress Kibana-4.1.8 yang telah diunduh dari website Kibana dan pindahkan direktori hasil uncompress ke home directory user.
/Users/hennywijaya/kibana/kibana-4.5.1-darwin-x64Kedua, start Kibana dari home directory Kibana-4.1.8
cd ~/kibana/kibana-4.1.8-darwin-x64/Setelah ini Kibana seharusnya sudah bisa diakses via web browser dengan URL
bin/kibana
http://ElasticsearchHostname:5601 (dalam contoh ini hostname Elasticsearch adalah localhost, oleh karena itu silakan akses Kibana via URL http://localhost:5601.4. Instal Apache Nutch versi 2.3.1
Pertama, uncompress file Apache Nutch versi 2.3.1 yang telah diunduh dari website Apache Nutch ke home directory user.
/Users/hennywijaya/nutch/apache-nutch-2.3.1Catatan: sampai dengan artikel ini disusun, Apache Nutch versi 2.3.1 belum tersedia binary file-nya, jadi kita mesti download source file apache-nutch-2.3.1 dan meng-compile-nya sendiri. Sebelum di-compile, kite mesti mengedit file konfigurasi nutch-site.xml pada direktori konfigurasi, yaitu:
/Users/hennywijaya/nutch/apache-nutch-2.3.1/conf cd ~/nutch/apache-nutch-2.3.1/confKedua, edit
nano nutch-site.xml
nutch-site.xml untuk menyatakan MongoDB sebagai GORA Backend (media penyimpanan data) untuk Apache Nutch.
<configuration>
<property>
<name>storage.data.store.class</name>
<value>org.apache.gora.mongodb.store.MongoStore</value>
<description>Default class for storing data.</description>
</property>
</configuration>
$NUTCH_HOME/ivy/ivy.xmlcd ~/nutch/apache-nutch-2.3.1/ivyHilangkan tanda komen (Uncomment) baris berikut pada file
nano ivy.xml
ivy.xml
...
<dependency org="org.apache.gora" name="gora-mongodb" rev="0.6.1" conf="*->default" />
...
</dependency>
$NUTCH_HOME/conf/gora.propertiescd ~/nutch/apache-nutch-2.3.1/conf
cat gora.properties
...
############################
# MongoDBStore properties #
############################
gora.datastore.default=org.apache.gora.mongodb.store.MongoStore
gora.mongodb.override_hadoop_configuration=false
gora.mongodb.mapping.file=/gora-mongodb-mapping.xml
gora.mongodb.servers=localhost:27017
gora.mongodb.db=nutch
ant runtime pada home directory apache-nutch-2.3.1 sebagai berikut (catatan: komputer harus tetap terhubung dengan Internet): cd ~/nutch/apache-nutch-2.3.1/
ant runtime
Buildfile: /Users/hennywijaya/nutch/apache-nutch-2.3.1/build.xml
Trying to override old definition of task javac
ivy-probe-antlib:
ivy-download:
ivy-download-unchecked:
ivy-init-antlib:
ivy-init:
init:
clean-lib:
resolve-default:
[ivy:resolve] :: Apache Ivy 2.3.0 - 20130110142753 :: http://ant.apache.org/ivy/ ::
[ivy:resolve] :: loading settings :: file = /Users/hennywijaya/nutch/apache-nutch-2.3.1/ivy/ivysettings.xml
[ivy:resolve] downloading
http://repo1.maven.org/maven2/org/apache/solr/solr-solrj/4.6.0/solr-solrj-4.6.0.jar ...
[ivy:resolve] .....................................................................................
...
BUILD SUCCESSFUL
Total time: 52 minutes 41 seconds
Buildfile: /Users/hennywijaya/nutch/apache-nutch-2.3.1/build.xml
Trying to override old definition of task javac
[taskdef] Could not load definitions from resource org/sonar/ant/antlib.xml. It could not be found.
ivy-probe-antlib:
ivy-download:
[taskdef] Could not load definitions from resource org/sonar/ant/antlib.xml. It could not be found.
<taskdef uri="antlib:org.sonar.ant" resource="org/sonar/ant/antlib.xml">
<classpath path="${ant.library.dir}"/>
<classpath path="${mysql.library.dir}"/>
</taskdef>
5. Memulai crawling atau menyerap isi website yang dijadikan target.
Sebelum dapat memulai crawling atau menyerap isi website yang dijadikan target menggunakan Apache Nutch, ada 2 konfigurasi yang mesti di-edit, yaitu:
Pertama, edit crawl properties, paling tidak crawler-nya diberi nama sehingga dapat dikenali oleh servers lain.
Kedua, tentukan URL-URL yang akan dijadikan target crawling.
Mari dimulai dengan konfigurasi pertama, yaitu mengedit crawl properties dengan terlebih dahulu masuk ke direktori apache-nutch-2.3.1 hasil compile.
cd ~/nutch/apache-nutch-2.3.1/runtime/local/Dalam direktori conf dapat ditemukan file
cd conf
nutch-default.xml yang berisi default crawl properties. Pada dasarnya, nutch-default.xml dapat dibiarkan apa adanya, tanpa diedit, dan crawling dapat dieksekusi. Namun, untuk kasus tertentu, dapat saja diedit sesuai keperluan. File konfigurasi dalam direktori conf yang harus diedit adalah
nutch-site.xml yang berfungsi sebagai tempat untuk menambahkan custom crawl properties yang akan meng-overwrite konfigurasi pada nutch-default.xml. Contoh konfigurasinya adalah sebagai berikut (catatan: property elastic.cluster harus sama dengan cluster.name pada konfigurasi Elasticsearch yang terdapat pada file config/elasticsearch.yml yang dalam hal ini value-nya adalah nasional-security-analysis):
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed to the Apache Software Foundation (ASF) under one or more
contributor license agreements. See the NOTICE file distributed with
this work for additional information regarding copyright ownership.
The ASF licenses this file to You under the Apache License, Version 2.0
(the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>storage.data.store.class</name>
<value>org.apache.gora.mongodb.store.MongoStore</value>
<description>Default class for storing data.</description>
</property>
<property>
<name>http.agent.name</name>
<value>Nasional Security Crawler</value>
</property>
<property>
<name>plugin.includes</name>
<value>protocol-(http|httpclient)|urlfilter-regex|index-(basic|more)|query-(basic|site|url|lang)|indexer-elastic|nutch-extensionpoints|parse-(text|html|msexcel|msword|mspowerpoint|pdf)|summary-basic|scoring-opic|urlnormalizer-(pass|regex|basic)|parse-(html|tika|metatags)|index-(basic|anchor|more|metadata)</value>
</property>
<property>
<name>elastic.host</name>
<value>localhost</value>
</property>
<property>
<name>elastic.cluster</name>
<value>nasional-security-analysis</value>
</property>
<property>
<name>elastic.index</name>
<value>nutch</value>
</property>
<property>
<name>parser.character.encoding.default</name>
<value>utf-8</value>
</property>
<property>
<name>http.content.limit</name>
<value>6553600</value>
</property>
</configuration>
seed.txt yang disimpan dalam direktori urls di home direktori apache-nutch-2.3.2 hasil compile. cd ~/nutch/apache-nutch-2.3.1/runtime/local/Sebagai tambahan, konfigurasi juga dapat dilakukan pada Regular Expression Filters yang terdapat pada file
mkdir -p urls
echo 'http://www.detik.com' > urls/seed.txt
cat urls/seed.txt
http://www.detik.com
conf/regex-urlfilter.txt. Caranya, edit file conf/regex-urlfilter.txt dan ganti baris berikut: dengan regular expression yang sesuai dengan domain name yang akan dijadikan target crawling. Sebagai contoh, jika crawling hanya ditujukan terhadap domain detik.com, regular expression-nya adalah seperti berikut:
# accept anything else
+.
Hasilnya, semua URL pada domain detik.com akan dijadikan target crawling. Setelah konfigurasi lengkap, proses crawling dilakukan dengan mengeksekusi 6 perintah secara berurutan. Enam perintah tersebut di-eksekusi dalam home direktori apache-nutch-2.3.1 hasil compile, yaitu: /Users/hennywijaya/nutch/apache-nutch-2.3.1/runtime/local
# include any URL in the domain detik.com
+^http://([a-z0-9]*\.)*detik.com/
cd ~/nutch/apache-nutch-2.3.1/runtime/local/
1) Inisiasi crawldb
bin/nutch inject urls
InjectorJob: starting at 2016-06-27 17:24:27
InjectorJob: Injecting urlDir: urls
InjectorJob: Using class org.apache.gora.mongodb.store.MongoStore as the Gora storage class.
InjectorJob: total number of urls rejected by filters: 0
InjectorJob: total number of urls injected after normalization and filtering: 1
Injector: finished at 2016-06-27 17:25:06, elapsed: 00:00:39
2) Generate URLs dari crawldb
bin/nutch generate -topN 80
GeneratorJob: starting at 2016-06-27 17:25:36
GeneratorJob: Selecting best-scoring urls due for fetch.
GeneratorJob: starting
GeneratorJob: filtering: true
GeneratorJob: normalizing: true
GeneratorJob: topN: 80
GeneratorJob: finished at 2016-06-27 17:26:11, time elapsed: 00:00:35
GeneratorJob: generated batch id: 1467015936-392613382 containing 80 URLs
3) Fetch generated URLs
bin/nutch fetch -all
FetcherJob: starting at 2016-06-27 17:27:07
FetcherJob: fetching all
FetcherJob: threads: 10
FetcherJob: parsing: false
FetcherJob: resuming: false
FetcherJob : timelimit set for : -1
Using queue mode : byHost
Fetcher: threads: 10
QueueFeeder finished: total 79 records. Hit by time limit :0
fetching http://diniii.blogdetik.com/2016/05/26/senangnya-jika-mendapatkan-tshirt-dari-blogdetik (queue crawl delay=5000ms)
fetching http://cevanofficial.blogdetik.com/2016/06/24/perencanaan-keuangan-berbasis-produk-syariah (queue crawl delay=5000ms)
fetching http://dadan.blogdetik.com/2016/06/15/ajarkan-si-kecil-berpuasa (queue crawl delay=5000ms)
fetching http://detik.com/dapur/beriklan (queue crawl delay=5000ms)
...
10/10 spinwaiting/active, 43 pages, 9 errors, 1.2 0 pages/s, 139 55 kb/s, 36 URLs in 1 queues
fetching http://blog.detik.com/kabarblog/3765/dapatkan-hadiah-uang-tunai-jutaan-rupiah-dengan-mengikuti-puasa-disini (queue crawl delay=5000ms)
10/10 spinwaiting/active, 44 pages, 9 errors, 1.1 0 pages/s, 131 76 kb/s, 35 URLs in 1 queues
...
fetching http://news.detik.com/ (queue crawl delay=5000ms)
-finishing thread FetcherThread1, activeThreads=1
-finishing thread FetcherThread2, activeThreads=1
-finishing thread FetcherThread3, activeThreads=1
-finishing thread FetcherThread4, activeThreads=1
-finishing thread FetcherThread5, activeThreads=1
-finishing thread FetcherThread6, activeThreads=1
-finishing thread FetcherThread7, activeThreads=1
-finishing thread FetcherThread8, activeThreads=1
Fetcher: throughput threshold: -1
-finishing thread FetcherThread9, activeThreads=1
Fetcher: throughput threshold sequence: 5
-finishing thread FetcherThread0, activeThreads=0
0/0 spinwaiting/active, 1 pages, 0 errors, 0.2 0 pages/s, 344 344 kb/s, 0 URLs in 0 queues
-activeThreads=0
FetcherJob: finished at 2016-06-27 17:32:12, time elapsed: 00:05:04
4) Parse fetched URLs
bin/nutch parse -all
ParserJob: starting at 2016-06-27 17:34:28
ParserJob: resuming: false
ParserJob: forced reparse: false
ParserJob: parsing all
Parsing http://news.detik.com/
Parsing http://antonlasoed.blogdetik.com/
Parsing http://antonlasoed.blogdetik.com/2016/05/26/aneka-rasa-saat-tulisan-jadi-headline
Parsing http://aribicara.blogdetik.com/
...
Parsing http://blogdetik.com/
Parsing http://cnnindonesia.com/ekonomi/20160627104538-92-141141/tol-trans-jawa-kurangi-40-persen-kepadatan-lalu-lintas/
Parsing http://cnnindonesia.com/internasional/20160627102815-120-141136/senjata-cia-untuk-pemberontak-suriah-dijual-di-pasar-gelap/
Parsing http://cnnindonesia.com/nasional/20160627103754-20-141139/mengenal-pembeda-vaksin-palsu-dan-dampaknya/
...
Parsing http://detik.com/dapur/kotak-pos
Parsing http://detik.com/dapur/pedoman-media
Parsing http://detik.com/dapur/privacy-policy
Parsing http://detik.com/dapur/redaksi
ParserJob: success
ParserJob: finished at 2016-06-27 17:35:10, time elapsed: 00:00:42
5) Update database dengan hasil parsing URLs
bin/nutch updatedb -all
DbUpdaterJob: starting at 2016-06-27 17:36:03
DbUpdaterJob: updatinging all
DbUpdaterJob: finished at 2016-06-27 17:36:41, time elapsed: 00:00:37
6) Membuat index URLs yang telah melewati proses parsing
bin/nutch index -all
IndexingJob: starting
Active IndexWriters :
ElasticIndexWriter
elastic.cluster : elastic prefix cluster
elastic.host : hostname
elastic.port : port (default 9300)
elastic.index : elastic index command
elastic.max.bulk.docs : elastic bulk index doc counts. (default 250)
elastic.max.bulk.size : elastic bulk index length. (default 2500500 ~2.5MB)
IndexingJob: done.
Nah, sampai disini, isi website yang dijadikan target crawling sudah berhasil disedot/diserap dengan Nutch dan telah di-index oleh Elasticsearch. Selanjutnya, data hasil crawling dapat di-visualisasikan dengan menggunakan Kibana.
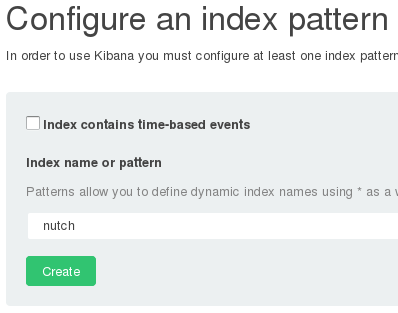
Gunakan web browser untuk mengakses Kibana di http://localhost:5601. Namun, sebelum data yang telah di-index Elasticsearch dapat ditampilkan, Kibana harus diberitahu nama index dari dataset yang ingin ditampilkan. Pada "Configure an index pattern" di halaman Kibana (http://localhost:5601), uncheck item "Index contains time-based events" dan ketik "nutch" pada field "Index name or pattern". Nama index "nutch" disini harus sama dengan nama index yang telah dikonfigurasi di nutch-site.xml pada property elastic.index seperti berikut:
<property>
<name>elastic.index</name>
<value>nutch</value>
</property>

Catatan:
Apache-nutch-2.3.1 TIDAK kompatibel dengan elasticsearch-2.3.3 Pasangan yang sudah dipastikan kompatibel adalah: apache-nutch-2.3.1 + elasticsearch-1.4.4 + kibana-4.1.8 + mongodb-3.2.1
Demikian, semoga bermanfaat. Silakan share pertanyaan, opini, maupun pengalaman anda via kolom komentar. Terima kasih.
Setelah sukses pada Bagian 2 ini, silakan lanjut ke Bagian 3 (Apache Nutch Crawl Script: Web Crawling hanya dengan Satu Command).


Komentar
Posting Komentar