Pentingnya Web Crawling sebagai Cara Pengumpulan Data di Era Big Data
Apa itu Web Crawler?
Web crawler atau yang dikenal juga dengan istilah web spider atau web robot adalah program yang bekerja dengan metode tertentu dan secara otomatis mengumpulkan semua informasi yang ada dalam suatu website. Web crawler akan mengunjungi setiap alamat website yang diberikan kepadanya, kemudian menyerap dan menyimpan semua informasi yang terkandung didalam website tersebut. Setiap kali web crawler mengunjungi sebuah website, maka dia juga akan mendata semua link yang ada dihalaman yang dikunjunginya itu untuk kemudian dikunjungi lagi satu persatu.Ketika crawlers menemukan halaman web, tugas selanjutnya adalah mengambil data-data dari halaman web dan menyimpannya ke dalam suatu media penyimpanan (harddisk). Data-data yang disimpan ini, nantinya dapat diakses pada saat dilakukan query yang berhubungan dengan data tersebut. Untuk mencapai tujuan mengumpulkan milyaran halaman web dan menyajikannya dalam hitungan detik, search engine membutuhkan data center yang sangat besar dan canggih untuk mengelola semua data ini.
Proses web crawler dalam mengunjungi setiap dokumen web disebut dengan web crawling atau spidering. Proses crawling dalam suatu website dimulai dari mendata seluruh url dari website, menelusurinya satu-persatu, kemudian memasukkannya dalam daftar halaman pada indeks search engine, sehingga setiap kali ada perubahan pada website, akan terupdate secara otomatis. Web crawling adalah proses mengambil kumpulan halaman dari sebuah web untuk dilakukan pengindeksan sehingga mendukung kinerja mesin pencari. Salah satu contoh situs yang menerapkan web crawling adalah www.webcrawler.com . Di samping situs-situ mesin pencari terkemuka tentunya, seperti Google, Yahoo, Ask, Live, dan lain sebagainya.
Web crawler biasa digunakan untuk membuat salinan secara sebagian atau keseluruhan halaman web yang telah dikunjunginya agar dapat diproses lebih lanjut oleh sistem penyusun index. Crawler dapat juga digunakan untuk proses pemeliharaan sebuah website, seperti memvalidasi kode html sebuah web, dan crawler juga digunakan untuk memperoleh data yang khusus seperti mengumpulkan alamat e-mail.
Web crawler termasuk kedalam bagian software agent atau yang lebih dikenal dengan istilah program bot. Secara umum crawler memulai prosesnya dengan memberikan daftar sejumlah alamat website untuk dikunjungi, disebut sebagai seeds. Setiap kali sebuah halaman web dikunjungi, crawler akan mencari alamat yang lain yang terdapat didalamnya dan menambahkan kedalam daftar seeds sebelumnya.
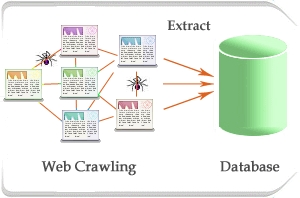
Web Crawling sebagai Salah Satu Cara Pengumpulan Data di Era Big Data
Perusahaan-perusahaan Fortune 500 layaknya Google dan Facebook telah berhasil memberdayakan Big Data untuk mengidentifikasi peluang-peluang bisnis, meningkatkan kualitas dan kuantitas layanan terhadap konsumennya, dan meningkatkan keuntungan.Mari kita ambil Google sebagai contoh kasus. Google telah mengumpulkan data dalam volume sangat besar dengan cara meng-crawl / mengorek / menyerap isi web page dari seluruh dunia. Dengan menggunakan data hasil crawling tersebut, yang dikombinasikan dengan data-data lain yang didapatkan dari kata-kata penelisikan (queries) yang diajukan via mesin pencarinya, Google telah berhasil meningkatkan efektifitas dari Google Adwords, dan dalam waktu yang sama juga meningkatkan kualitas pengalaman penggunanya saat melakukan pencarian. Sebagai hasilnya, Google sukses meningkatkan keuntungan untuk dirinya sendiri dan juga untuk pelanggan pengguna layanan Adwords, serta mampu meningkatkan kepuasan para penggunanya.
Untuk dapat membangun bisnis berbasis data dalam skala sekelas Google, tentu membutuhkan waktu, tenaga, dan biaya yang tidak sedikit. Jangankan dalam skala besar, bahkan untuk memulai membuat suatu produk ataupun layanan berbasis data pada level pemula dan dalam skala kecil saja juga bukan hal yang mudah. Salah satu alasan utama kenapa begitu sulit untuk menghasilkan suatu produk berbasis data adalah karena terlebih dahulu kita mesti mampu mengumpulkan data dalam volume raksasa sebelum kita bisa membuat suatu produk yang berbasiskan data tersebut. Data dapat kita dapatkan dengan beberapa cara, diantaranya:
1. Input langsung dari pelanggan, melalui survey maupun angket.
2. Menggunakan API pihak ketiga seperti Facebook API, Twitter API dan sebagainya.
3. Log Web Server seperti Apache dan Nginx
4. Dengan melakukan Web Crawling atau Web Scraping
Dari cara-cara pengumpulan data tersebut, sebagian besar perusahaan berbasis data pada kenyataannya menggunakan web crawler karena kebanyakan data yang dibutuhkan oleh perusahaan-perusahaan ini adalah dalam bentuk web page yang tidak bisa diakses menggunakan API tertentu. Namun demikian, meng-crawl web page bukanlah perkara mudah. Web adalah lautan informasi dengan miliaran web pages (laman web) dibuat setiap hari. Sebagian besar dari laman web tersebut memuat data-data yang tak berstruktur dan berantakan. Mengumpulkan dan mengorganisir data-data yang berantakan ini tentu bukan hal yang mudah dilakukan.2. Menggunakan API pihak ketiga seperti Facebook API, Twitter API dan sebagainya.
3. Log Web Server seperti Apache dan Nginx
4. Dengan melakukan Web Crawling atau Web Scraping
Dalam proses pembuatan produk yang berbasis data, kurang lebih 90 persen waktu kita akan habis untuk pengumpulan, pembersihan, dan penyaringan data. Satu lagi, saat kita akan melakukan web crawling, kita dipastikan mesti memiliki kemampuan programming dan database yang tak setengah-setengah. Tak akan ada data dari laman web yang bisa langsung siap pakai untuk memenuhi keperluan kita sesuai spesifikasi yang diharapkan. Oleh karena itu, banyak perusahaan yang akhirnya memperkerjakan programmer mumpuni dan ilmuwan data (data scientist) untuk menjalankan web crawling dan analisis data yang memaksa mereka untuk mengeluarkan biaya yang tidak tanggung-tanggung.
Kesimpulan : Web Crawling Punya Peran Signifikan di Era Big Data
Kesimpulannya, pada tahun-tahun mendatang, kita akan masih mendengar banyak berita tentang Big Data dan perusahaan-perusahaan baru yang berbasis data. Perusahaan yang lebih memahami Big Data akan mampu menyuguhkan pengalaman yang lebih baik kepada para pelanggannya, mampu untuk menemukan pelanggan yang potensial, dan tentu mampu menghasilkan keuntungan yang lebih besar. Web crawling adalah bagian yang sangat penting dalam mengembangkan hampir semua produk ataupun layanan yang berbasis data. -->Lanjut, membangun Web crawler:
1. Web Crawling: Menyerap isi Website dan Membangun Mesin Pencari ala Google Menggunakan Apache Nutch, Elasticsearch, dan MongoDB – bagian 1/3
2. Web Crawling: Menyerap isi Website dan Membangun Mesin Pencari ala Google Menggunakan Apache Nutch, Elasticsearch, dan MongoDB – bagian 2/3
2. Web Crawling: Menyerap isi Website dan Membangun Mesin Pencari ala Google Menggunakan Apache Nutch, Elasticsearch, dan MongoDB – bagian 2/3


Komentar
Posting Komentar