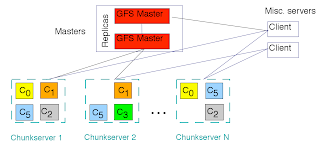
HDFS: Berawal dari Google untuk Big Data

Segala sesuatu mulai dari definisi HDFS adalah singkatan dari Hadoop Distributed File System. Kalau diterjemahkan mentah-mentah, maka HDFS adalah Sistem File Terdistribusi Hadoop. Hadoop adalah salah satu proyek open source milik Apache. Jadi HDFS adalah sistem file terdistribusi yang dikembangkan oleh Apache dalam proyeknya yang bernama Hadoop. Apache mengembangkan HDFS berdasarkan konsep dari Google File System (detailnya simak: GoogleFile System: Menggotong-royongkan Ribuan Komputer ala Google ). Oleh karena itu, HDFS sangat mirip dengan Google File System baik ditinjau dari konsep logikanya, struktur fisik, maupun cara kerjanya. Lalu, sistem file terdistribusi itu apa? Sederhananya, distributed file system (sistem file terdistribusi) adalah file system yang menyimpan data tidak dalam satu hard disk drive (HDD) atau media penyimpanan lainnya, tetapi data dipecah-pecah dan disimpan tersebar dalam suatu cluster yang terdiri atas beberapa komputer, bisa hanya 2 komputer, puluhan bahkan...